为了对ORACLE数据库有一个基本的了解,我们首先需要理解ORACLE的内存结构。
可以大体上将ORALCE内存分为以下几类:
- System Global area(SGA)
一组共享内存结构,包含数据库实例的数据以及控制信息。 - Program global area(PGA)
进程或者线程独占的内存结构。当ORACLE进程启动时分配该内存。 - User global area(UGA)
与用户会话相关的内存结构。 - Software code areas
用于存储正在运行或可能运行的代码的内存区域。
oracle整体内存结构如下图
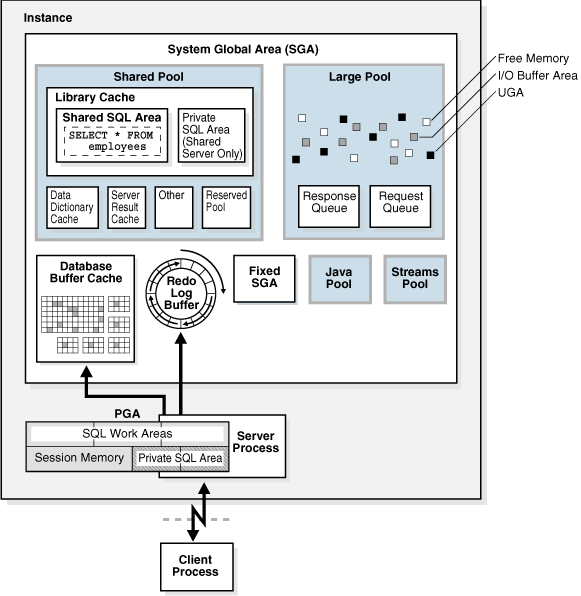
UGA-User Global Area
UGA是一块用来存储会话状态相关的内存区域。取决于是否通过shared server模式连接,它可能存在于SGA或者PGA中。
Shared Server – UGA存在于SGA中
Dedicated Server – UGA存在于PGA中
PGA-Program Global Area
PGA是特定于操作系统进程或线程的内存。下图是dedicated server模式下PGA包含的区域——SQL工作区、私有SQL区和会话内存(在shared server模式下私有SQL区存在于SGA中):
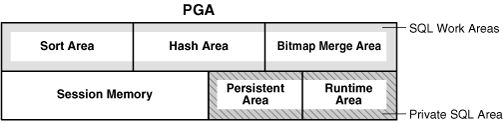
私有SQL区
存储变量的绑定信息以及运行时的内存结构。在dedicated server模式下该内存区域位于PGA中,但是在shared server模式下在SGA中。该内存区域由客户端管理该区域的创建,服务器端的OPEN_CURSORS参数限定可分配的上限。
- persistent area
存储变量绑定的值,当游标关闭时释放该区域内存。 - run-time area
当发起query execute请求时,首先会创建该区域,用于存储相关状态信息。例如,做全表扫描时,已检索的行数。
SQL工作区
用于排序、位图合并、哈希连接等内存密集型的操作,这些操作会首先在SQL WORK AREA中进行,当分配的内存空间不足时将部分数据写入磁盘的TEMPSPACE表空间。
SGA-System Global Area
SGA属于数据库实例的一部分。可通过V$SGASTAT查看各个内存区域的基本信息。
Database Buffer Cache
用于缓存当前或最近使用的从磁盘读取的数据块的拷贝,来优化数据库的I/O减少物理读/写。Oralce依据LRU算法对该内存区域进行block-level的更新。
当一个客户端进程请求数据时,服务端进程会首先去查找buffer cache,如果命中,数据库就进行逻辑读获取该buffer cache的数据。如果未查找到数据,并且数据库开启了flash cache那么服务端进程会查找 flash cache LRU List的buffer header,如果发现数据,则将flash cache中的数据加载到内存中。当以上方式都未读取到数据时,数据库就会进行一次物理读:首先将数据库复制到内存中,然后执行逻辑读操作返回数据。oracle数据库的一般数据读取流程就是这样,但是在进行Full Table Scan时情况可能有些不同。
在默认情况下,当从磁盘读取数据时,会将读取到的缓存在LRU链表的中间位置,以此保证经常使用的数据块依然保留在buffer cache中。但是在进行全表扫描时,很有可能我们读取的数据块大小超过了buffer cache的大小,如果直接放进内存则会将内存中原本的数据全都age out出去,这样势必会导致数据库性能的下降。
在进行全表扫描时,如果一个表所需的内存占buffer cache很小的一个百分比,那么就会将其加载至内存中。对一个中等大小的表,数据库会权衡最后一次表扫描,buffer cache的老化时间戳和buffer cache中剩余空间等因素来决定是否将其加载到内存中。对于一个很大的表,那么数据库就倾向于直接使用direct path read,直接把数据加载到PGA中,避免频繁的age out buffer cache中的数据块。当然我们也可以使用ALTER TABLE ... CACHE来将大表的数据缓存到buffer Cache中。
当我们执行DML语句对数据进行更新的时候也是会在buffer cache中操作的,更新后的数据会在以下情况将脏数据写回磁盘:
- 当无法找到clean buffer来读取数据块
- 数据库执行检查点
- 更改表空间状态为只读或离线状态
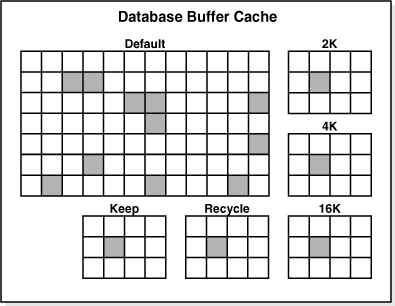
大多数时候我们说的buffer cache指的是默认的Default Buffer Pool,根据不同用途和大小,还有很多不同类型的buffer pool:
- Default Buffer Pool:缺省情况下的Cache,他的大小由DB_CACHE_SIZE指定
- Keep Buffer Pool:该内存区域用于缓存那些需要经常使用但是又总是被age out出Default Buffer Pool的数据,其大小由
DB_KEEP_CACHE_SIZE指定。可使用ALTER TABLE ... STORAGE BUFFER_POOL KEEP语句来修改表的默认缓存位置为Keep Buffer Pool。 - Recycle Buffer Pool:放在这个区域中的数据一用完就会被移出。对于 那些体积巨大、偶尔使用的表,可以考虑放在这个内存中,以尽快释放内存
- 以上的Buffer Pool都只适用于标准大小的数据块。默认情况下创建的表空间都是使用的8K数据块,当我们创建非标准数据块的表空间(如:2K,4K,16K)这些数据块则会放进其单独的pool中。
Redo Log Buffer
redo log buffer是一个循环缓冲区,用于LGWR进程将redo entries写入redo log前缓存该数据。该区域通常只有几MB,当一个进程执行DML或者DDL操作时,数据库会记录下该操作产生一条Redo record,并保存到Redo Log Buffer中。以下情况,LGWR进程会把redo buffer中的数据写到redo log file中:
- 每3秒
- 执行commit语句
- 执行switch log files操作时
- redo buffer使用超过1/3或者占用内存操作1M时
- DBW进程必须把数据写入磁盘之前
Shared Pool
Shared Pool是一块非常重要的内存区域,特别是对于OLTP系统而言,其中保存了各种类型的程序数据:PL/SQL代码,解析的查询语句,执行计划,系统参数,数据字典等。对于shared server模式,该内存区域也含括了private SQL area。
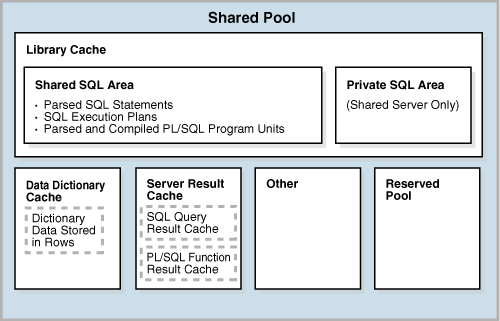
其中Library cache用来存储可执行的SQL或PL/SQL代码所对应的执行计划、解析树、Pcode、Mcode等对象以及控制结构(如,锁和库缓存句柄),当我们再次执行相应的代码时就无语再从头开始进行解析。我们存放在Library cache中的对象,称为库缓存对象,oracle通过库缓存句柄来访问库缓存对象。Data dictionary cache则用于存储数据库对象的相关信息,在执行SQL语句解析期间会频繁的访问该内存区域。
在Library cache中我们主要关注的是CRSR这类库缓存对象(SQL和匿名PL/SQL对象)称为shared cursor,涉及到SQL的解析,对于OLTP系统而言至关重要。
shared cursor又可以分为parent cursor和child cursor可以分别通过V$SQLAREA和V$SQL查看对应的cursor。parent cursor存储目标SQL的SQL文本,而child cursor存储解析树和执行计划。
oracle在解析目标SQL时去库缓存查询shared cursor的流程如下:
- 根据目标SQL的hash值去寻找对应的Hash Bucket,不同的SQL有可能产生相同的hash值,相同的SQL不同的语义也会产生相同的Hash值。
- 在Hash Bucket中查找匹配的Parent cursor,解决了不同SQL产生相同hash值得问题。
- 再查找匹配的child cursor,解决相同的SQL不同的语义也会产生相同的Hash值问题。
- 找到对应的child cursor后oracle直接把对应的解析树和执行计划拿去重用。
test_env和test_env1都有相同的表tb_table_list,执行相同的sql后,他们有共同的parent cursor但是对应的child cursor是不同的。
test_env用户执行
1 | SQL> select count(*) from tb_table_list; |
test_env1用户执行
1 | SQL> select count(*) from tb_table_list; |
接下来分别查看parent cursor和child cursor
1 | SQL> select sql_text,sql_id,version_count from v$sqlarea where sql_text like 'select count(*) from tb_table%'; |
VERSION_COUNT表示某个parent cursor拥有的child cursor数量。可以看到对于相同的sql语句,所生产的parent cursor是相同的,但是对应了不同的解析树和执行计划,应为两个tb_table_list属于不同的用户。
如果在library cache中并没有找到对应SQL的解析树和执行性计划,那么此时就会产生OLTP系统的万恶之源——硬解析。对于一个高并发的系统,频繁的进行硬解析会导致严重Latch和Mutex的争用,使系统性能下降。
Large Pool、Java Pool和Fixed SGA
Large Pool主要用于RMAN备份时I/O子系统缓存以及并发执行语句的消息缓存。Java pool则用于支撑java虚拟机相关内存需求。Fixed SGA是oracle内部管理的一块区域,不能被修改,只会因为oralce数据库版本的不同而有可能产生差异。